Show setup information.
knitr::opts_chunk$set(collapse = TRUE)
pacman::p_load(kableExtra, DT, htmlwidgets, htmltools,
DiagrammeR, DiagrammeRsvg, rsvg, readr,
tidyverse, plyr, data.table,
install = FALSE, update = FALSE)Data Availability
All files generated in this workflow can be downloaded from figshare.
File names and descriptions:
- 01_MAG02_PAN Pangenomic analysis of MAG02.
- 02_MAG02_PHYLOGENOMICS Phylogenomic analysis of MAG02.
- 03_MAG02_16S_rRNA_PHYLOGENETICS 16S rRNA phylogenetic analyses of MAG02. You can use the anvi’o commands described in the workflow to visualize the data.
What we want to do next is compare MAG021 to publicly available genomes. We know from our binning and binning summary that MAG02 has a lot of hits to Arcobacter, an Epsilonproteobacteria. However, when we run anvi-estimate-scg-taxonomy we get something a little different.
anvi-estimate-scg-taxonomy -c 18_NR-MAGs-SPLIT/WATER_MAG_00002/CONTIGS.db| MAG | total_scgs | supporting_scgs | taxonomy |
|---|---|---|---|
| WATER_MAG_00002 | 20 | 9 | Bacteria / Campylobacterota / Campylobacteria / Campylobacterales / Arcobacteraceae / Poseidonibacter / Poseidonibacter sp002470185 |
Hum. Poseidonibacter. A little disagreement between the SCG classification and the short-read classification. Not too big of a deal since Poseidonibacter is in the Arcobacteraceae.
Getting Genomes from NCBI
For this workflow we largely follow the tutorial on Accessing and including NCBI genomes in ’omics analyses in anvi’o by Alon Shaiber and Meren.
We need genomes to compare to our MAG. As the tutorial explains, we can either use the taxa name itself or the TaxID. But before that we need to get the gimme_taxa.py helper script by by Joe R. J. Healey that allows us to download genomes from NCBI. Slick.
wget https://raw.githubusercontent.com/kblin/ncbi-genome-download/master/contrib/gimme_taxa.pyWe can start with the taxa names themselves.
Getting TaxIDs to Download
python gimme_taxa.py Poseidonibacter \
-o Poseidonibacter-for-ngd.txt
python gimme_taxa.py Arcobacter \
-o Arcobacter-for-ngd.txtWe only got 1 hit for Poseidonibacter but the script returned 48 for Arcobacter.
What about the TaxID?
We need to head to NCBI’s Taxonomy Browser and get the parent TaxID by searching for the taxon name of interest, in this case Poseidonibacter and Arcobacter.
Poseidonibacter is TaxID 2321187 and Arcobacter is TaxID 28196.
python gimme_taxa.py 2321187 \
-o Poseidonibacter-TaxIDs-for-ngd.txt
python gimme_taxa.py 28196 \
-o Arcobacter-TaxIDs-for-ngd.txtIn this case the results of using TaxID and taxon name were identical, however that is not always the case, so it is good to check.
On the taxonomy browser, both genera are part of the Arcobacter group. Since there is some ambiguity as to the identification of MAG02, we will instead use the entire group.
python gimme_taxa.py 2321108 \
-o Arcobacter_Group-TaxIDs-for-ngd.txtThis time we get 198 hits. Since we only need the TaxIDs, we can rerun the command like so:
python gimme_taxa.py 2321108 \
-o Arcobacter_Group-TaxIDs-for-ngd-just-IDs.txt \
--just-taxidsAs the command implies, we only get a list of TaxIDs. Moving on,
Downloading Genomes from NCBI
To download genomes using the TaxIDs, we need a collection of scripts called ncbi-genome-download. See the GitHub repo for installation instructions. We have a choice of where to look for genomes using the -s flag—either Genbank or Refseq
ncbi-genome-download -t Arcobacter_Group-TaxIDs-for-ngd-just-IDs.txt \
bacteria \
-o 00_Arcobacter_Genbank \
--metadata Arcobacter-NCBI-METADATA.txt \
-s genbankWe tested both options and found that the -s genbank returned 121 genomes and -s refseq returned 95. We compared the two lists and found nothing unique in the Refseq database so we will continue with the GenBank set.
After all of this hullabaloo, turns out Poseidonibacter was not part of the download. Curious. Anyway, we ran an additional instance of the command to get these genomes. The command did not work with the TaxID so we had to use the genus name instead. At this point, can you believe anything I say? Well, you shouldn’t.
ncbi-genome-download bacteria \
-g Poseidonibacter \
-o 00_Arcobacter_Genbank \
--metadata Poseidonibacter-NCBI-METADATA.txt \
-s genbankProcessing NCBI Genomes
A metadata file is also created by ncbi-genome-download.
column -t Arcobacter-NCBI-METADATA.txt | head -n 4assembly_accession bioproject biosample wgs_master excluded_from_refseq refseq_category relation_to_type_material taxid species_taxid organism_name infraspecific_name isolate version_status assembly_level release_type genome_rep seq_rel_date asm_name submitter gbrs_paired_asm paired_asm_comp ftp_path local_filename
GCA_000014025.1 PRJNA16319 SAMN02604276 representative genome assembly from type material 367737 28197 Arcobacter butzleri RM4018 strain=RM4018 latest Complete Genome Major Full 9/27/07 ASM1402v1 USDA - Agricultural Research Service, USA GCF_000014025.1 identical ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/000/014/025/GCA_000014025.1_ASM1402v1 ./Arcobacter_Genbank/genbank/bacteria/GCA_000014025.1/GCA_000014025.1_ASM1402v1_genomic.gbff.gz
GCA_000185325.1 PRJNA53195 SAMN00210774 AEPT00000000.1 na 888827 28197 Arcobacter butzleri JV22 strain=JV22 latest Scaffold Major Full 1/14/11 ASM18532v1 Baylor College of Medicine GCF_000185325.1 identical ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/000/185/325/GCA_000185325.1_ASM18532v1 ./Arcobacter_Genbank/genbank/bacteria/GCA_000185325.1/GCA_000185325.1_ASM18532v1_genomic.gbff.gz
GCA_000215345.3 PRJNA67167 SAMN02604193 na 1036172 28197 Arcobacter butzleri 7h1h strain=7h1h latest Complete Genome Major Full 7/24/13 ASM21534v3 University of Liverpool GCF_000215345.2 identical ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCA/000/215/345/GCA_000215345.3_ASM21534v3 ./Arcobacter_Genbank/genbank/bacteria/GCA_000215345.3/GCA_000215345.3_ASM21534v3_genomic.gbff.gzAnvi’o has a script that takes this metadata file and generates a fasta.txt file in the format compatible with anvi’o workflows. We will use the --exclude-gene-calls-from-fasta-txt because we want to do our own gene calling.
anvi-script-process-genbank-metadata -m Arcobacter-NCBI-METADATA.txt \
-o 01_Arcobacter-NCBI-GENOMES \
--output-fasta-txt Arcobacter-fasta.txt
--exclude-gene-calls-from-fasta-txtThis command returns a directory, 01_Arcobacter-NCBI-GENOMES full of fasta files and the file Arcobacter-fasta.txt, which contains the name and fasta file path for each genome.
name path
Aliiarcobacter_faecis_GCA_000585155_1 /pool/genomics/stri_istmobiome/data/HYPOXIA_DATA/HYPOXIA/19_COMPARATIVE_GENOMICS/01_Arcobacter-NCBI-GENOMES/Aliiarcobacter_faecis_GCA_000585155_1-contigs.fa
Aliiarcobacter_faecis_GCA_013201705_1 /pool/genomics/stri_istmobiome/data/HYPOXIA_DATA/HYPOXIA/19_COMPARATIVE_GENOMICS/01_Arcobacter-NCBI-GENOMES/Aliiarcobacter_faecis_GCA_013201705_1-contigs.fa
Arcobacter_anaerophilus_GCA_000935065_1 /pool/genomics/stri_istmobiome/data/HYPOXIA_DATA/HYPOXIA/19_COMPARATIVE_GENOMICS/01_Arcobacter-NCBI-GENOMES/Arcobacter_anaerophilus_GCA_000935065_1-contigs.faWe need to add our MAG to the fasta directory and its name to the Arcobacter-fasta.txt file. We will also change the names produced by anvi-script-process-genbank-metadata since they are not very meaningful. We can use the Arcobacter-NCBI-METADATA.txt file, specifically the organism_name, infraspecific_name, and/or isolate columns to cobble together new genome names. I wish I could say I had a clever way to do this task, but really it was just some copying and pasting. Sadly, I am not as cool as Alon and Meren.
If you change the names they MUST be unique and contain no spaces, periods, dashes, or other weird characters. Letters, numbers, and underscores only.
Running Snakemake Contigs Workflow
Now it is time for some comparisons. First we will run the contigs workflow since this will produce annotated contig databases and properly formatted fasta files for all genomes. We will need these for phylogenomics. Ok, renamed file in hand, we use Snakemake workflow (Köster and Rahmann 2012) to run the built-in anvi’o contigs workflow. If you do not know what workflows are available you can run this command:
anvi-run-workflow --list-workflowsWARNING
===============================================
If you publish results from this workflow, please do not forget to cite
snakemake (doi:10.1093/bioinformatics/bts480)
Available workflows ..........................: contigs, metagenomics, pangenomics, phylogenomicsNext, we need a config file for the contigs workflow. This file tells anvi’o what commands to run and how to run them. We run this command to generate a default config file, which can be modified as you see fit. Some commands we chose not to run but they remain in the workflow for posterity.
anvi-run-workflow -w contigs --get-default-config contigs-default-config.jsonShow/hide JSON-formatted configuration file.
{
"fasta_txt": "Arcobacter-fasta-rename.txt",
"anvi_gen_contigs_database": {
"--project-name": "{group}",
"--description": "",
"--skip-gene-calling": "",
"--external-gene-calls": "",
"--ignore-internal-stop-codons": "",
"--skip-mindful-splitting": "",
"--contigs-fasta": "",
"--split-length": "",
"--kmer-size": "",
"--skip-predict-frame": "",
"--prodigal-translation-table": "",
"threads": ""
},
"centrifuge": {
"threads": 2,
"run": "",
"db": ""
},
"anvi_run_hmms": {
"run": true,
"threads": 5,
"--installed-hmm-profile": "",
"--hmm-profile-dir": "",
"--also-scan-trnas": ""
},
"anvi_run_ncbi_cogs": {
"run": true,
"threads": 5,
"--cog-data-dir": "/pool/genomics/stri_istmobiome/dbs/cog_db/",
"--sensitive": "",
"--temporary-dir-path": "/pool/genomics/stri_istmobiome/dbs/cog_db/tmp/",
"--search-with": ""
},
"anvi_run_scg_taxonomy": {
"run": true,
"threads": 6,
"--scgs-taxonomy-data-dir": "/pool/genomics/stri_istmobiome/dbs/scgs-taxonomy-data/tmp/"
},
"anvi_run_trna_scan": {
"run": true,
"threads": 6,
"--trna-cutoff-score": ""
},
"anvi_script_reformat_fasta": {
"run": true,
"--prefix": "{group}",
"--simplify-names": true,
"--keep-ids": "",
"--exclude-ids": "",
"--min-len": "",
"threads": ""
},
"emapper": {
"--database": "bact",
"--usemem": true,
"--override": true,
"path_to_emapper_dir": "",
"threads": ""
},
"anvi_script_run_eggnog_mapper": {
"--use-version": "0.12.6",
"run": "",
"--cog-data-dir": "",
"--drop-previous-annotations": "",
"threads": ""
},
"gen_external_genome_file": {
"threads": ""
},
"export_gene_calls_for_centrifuge": {
"threads": ""
},
"anvi_import_taxonomy_for_genes": {
"threads": ""
},
"annotate_contigs_database": {
"threads": ""
},
"anvi_get_sequences_for_gene_calls": {
"threads": ""
},
"gunzip_fasta": {
"threads": ""
},
"reformat_external_gene_calls_table": {
"threads": ""
},
"reformat_external_functions": {
"threads": ""
},
"import_external_functions": {
"threads": ""
},
"anvi_run_pfams": {
"run": true,
"--pfam-data-dir": "/pool/genomics/stri_istmobiome/dbs/pfam_db/",
"threads": ""
},
"output_dirs": {
"FASTA_DIR": "02_FASTA",
"CONTIGS_DIR": "03_CONTIGS",
"LOGS_DIR": "00_LOGS"
},
"max_threads": "",
"config_version": "1",
"workflow_name": "contigs"
}
We can also run a couple of sanity checks to make sure everything is good before starting the job. How about a workflow graph to visually inspect the steps?
anvi-run-workflow -w contigs -c contigs-default-config.json --save-workflow-graphConfig Error: Well, the fasta.txt entry name contains characters that anvi'o does not like :/
Please limit the characters to ASCII letters, digits, and the underscore ('_')
character.Hum? What did I tell you, don’t listen to me. Turns out I had dashes (-) in some genome names in the Arcobacter-fasta-rename.txt file. I took those out and reran the command.
WARNING
===============================================
If you publish results from this workflow, please do not forget to cite
snakemake (doi:10.1093/bioinformatics/bts480)
WARNING
===============================================
We are initiating parameters for the contigs workflow
WARNING
===============================================
You chose to define --temporary-dir-path for the rule anvi_run_ncbi_cogs in the
config file as /pool/genomics/stri_istmobiome/dbs/cog_db/tmp/. while this is
allowed, know that you are doing so at your own risk. The reason this is risky
is because this rule uses a wildcard/wildcards and hence is probably running
more than once, and this might cause a problem. In case you wanted to know,
these are the wildcards used by this rule: {group}
Workflow DOT file ............................: workflow.dot
Workflow PNG file ............................: workflow.pngSuccess. Let’s have a look at the workflow. Only four genomes are shown for clarity but each step will be conducted for all genomes.
Click on the image to zoom in or download a copy.
Show/hide DAG R Code script
````
```{r workflow2, eval=FALSE}
dag <- grViz ("
digraph boxes_and_circles {
graph [layout = dot, align=center]
node [shape = rectangle, style = 'rounded,filled' fontname=sans, fontsize=12, penwidth=4]
edge[penwidth=4, color=grey];
0[label = 'contigs_target_rule', color = 'grey'];
1[label = 'annotate_contigs_database', color = '#009E73'];
2[label = 'annotate_contigs_database', color = '#009E73'];
3[label = 'annotate_contigs_database', color = '#009E73'];
4[label = 'annotate_contigs_database', color = '#009E73'];
5[label = 'anvi_gen_contigs_database', color = '#009E73'];
6[label = 'anvi_run_hmms', color = '#CC79A7'];
7[label = 'anvi_run_ncbi_cogs', color = '#E69F00'];
8[label = 'anvi_run_scg_taxonomy', color = '#CC79A7'];
9[label = 'anvi_run_trna_scan', color = '#CC79A7'];
10[label = 'anvi_run_pfams', color = '#E69F00'];
11[label = 'anvi_gen_contigs_database', color = '#009E73'];
12[label = 'anvi_run_hmms', color = '#CC79A7'];
13[label = 'anvi_run_ncbi_cogs', color = '#E69F00'];
14[label = 'anvi_run_scg_taxonomy', color = '#CC79A7'];
15[label = 'anvi_run_trna_scan', color = '#CC79A7'];
16[label = 'anvi_run_pfams', color = '#E69F00'];
17[label = 'anvi_gen_contigs_database', color = '#009E73'];
18[label = 'anvi_run_hmms', color = '#CC79A7'];
19[label = 'anvi_run_ncbi_cogs', color = '#E69F00'];
20[label = 'anvi_run_scg_taxonomy', color = '#CC79A7'];
21[label = 'anvi_run_trna_scan', color = '#CC79A7'];
22[label = 'anvi_run_pfams', color = '#E69F00'];
23[label = 'anvi_gen_contigs_database', color = '#009E73'];
24[label = 'anvi_run_hmms', color = '#CC79A7'];
25[label = 'anvi_run_ncbi_cogs', color = '#E69F00'];
26[label = 'anvi_run_scg_taxonomy', color = '#CC79A7'];
27[label = 'anvi_run_trna_scan', color = '#CC79A7'];
28[label = 'anvi_run_pfams', color = '#E69F00'];
29[label = 'anvi_script_reformat_fasta', color = '#56B4E9'];
30[label = 'anvi_script_reformat_fasta', color = '#56B4E9'];
31[label = 'anvi_script_reformat_fasta', color = '#56B4E9'];
32[label = 'anvi_script_reformat_fasta', color = '#56B4E9'];
33[label = 'anvi_script_reformat_fasta_prefix_only\n Arcobacter_canalis', color = '#56B4E9'];
34[label = 'anvi_script_reformat_fasta_prefix_only\n Arcobacter_marinus', color = '#56B4E9'];
35[label = 'anvi_script_reformat_fasta_prefix_only\n Poseidonibacter', color = '#56B4E9'];
36[label = 'anvi_script_reformat_fasta_prefix_only\n MAG02', color = '#56B4E9'];
1->0; 2->0; 3->0; 4->0; 5->1; 6->1; 7->1;
8->1; 9->1; 10->1; 11->2; 12->2; 13->2; 14->2;
15->2; 16->2; 17->3; 18->3; 19->3; 20->3;
21->3; 22->3; 23->4; 24->4; 25->4; 26->4;
27->4; 28->4; 29->5; 5->6; 5->7; 6->8; 5->8;
5->9; 5->10; 30->11; 11->12; 11->13; 12->14;
11->14; 11->15; 11->16; 31->17; 17->18; 17->19;
18->20; 17->20; 17->21; 17->22; 32->23; 23->24;
23->25; 24->26; 23->26; 23->27; 23->28; 33->29;
34->30; 35->31; 36->32;
graph [nodesep = 0.1]
{ rank=same; 33, 34, 35, 36 }
}
")
export_svg(dag) %>%
charToRaw() %>%
rsvg() %>%
png::writePNG("figures/mag02-phylogenomics/workflow.png")
```
````
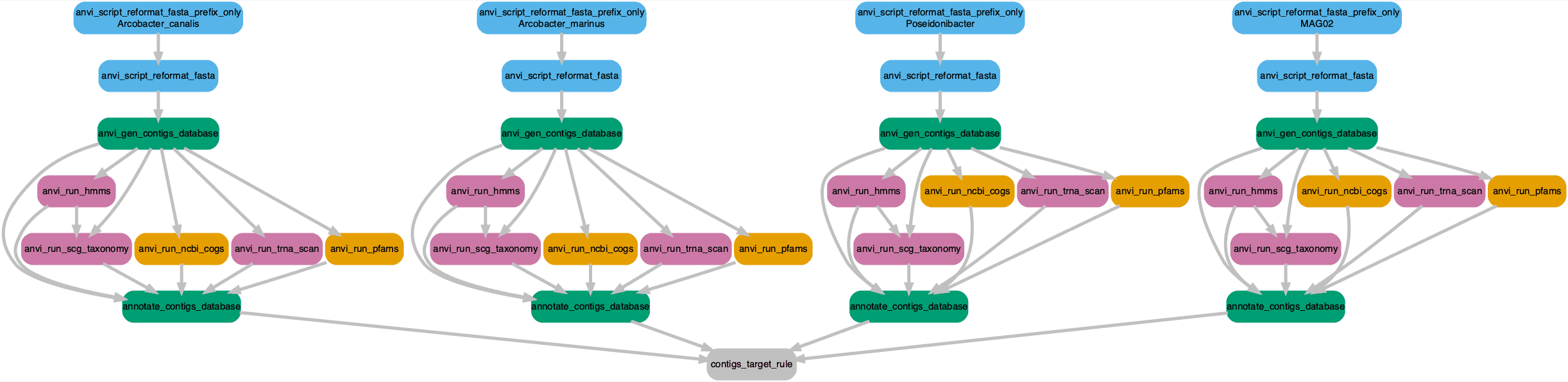
Yup. Looks good and makes sense. And a dry run just to be certain
anvi-run-workflow -w contigs -c contigs-default-config.json --dry-runNo complaints. Things are looking good. We are ready to run the workflow.
For all of you HYDRA users, here is the job script to run the contigs workflow.
Show/hide HYDRA SNAKEMAKE job script
# /bin/sh
# ----------------Parameters---------------------- #
#$ -S /bin/sh
#$ -pe mthread 20
#$ -q sThC.q
#$ -l mres=120G,h_data=6G,h_vmem=6G
#$ -cwd
#$ -j y
#$ -N job_01b_run_contigs_workflow
#$ -o hydra_logs/job_01b_run_contigs_workflow.log
#$ -M scottjj@si.edu
#
# ----------------Modules------------------------- #
module load gcc/4.9.2
#
# ----------------Your Commands------------------- #
#
echo + `date` job $JOB_NAME started in $QUEUE with jobID=$JOB_ID on $HOSTNAME
echo + NSLOTS = $NSLOTS
#
### CALLING ANVIO ###
export PATH=/home/scottjj/miniconda3:$PATH
export PATH=/home/scottjj/miniconda3/bin:$PATH
source activate anvio-master
#
#############################################
### Making sure everything is cool
which python
python --version
source /home/scottjj/virtual-envs/anvio-master/bin/activate
which python
python --version
which anvi-interactive
diamond --version
anvi-self-test -v
#############################################
#
## pfam tmp
rm -r /pool/genomics/stri_istmobiome/dbs/pfam_db/tmp_data/
mkdir -p /pool/genomics/stri_istmobiome/dbs/pfam_db/tmp_data/
TMPDIR="/pool/genomics/stri_istmobiome/dbs/pfam_db/tmp_data/"
#
anvi-run-workflow -w contigs -c contigs-default-config.json --additional-params --jobs 20 --resources nodes=20 --keep-going --rerun-incomplete --unlock
anvi-run-workflow -w contigs -c contigs-default-config.json --additional-params --jobs 20 --resources nodes=20 --keep-going --rerun-incomplete
#
echo = `date` job $JOB_NAME don
Finished? Sweet. What we have now are contig databases for 124 Arcobacter-group genomes—databases that contain gene calls, functional annotations, HMM profiles, etc. Remember, our goal is to better understand MAG02 by asking what it is related to and where related genomes are found in nature. Before continuing, we need to ask two questions about our genome collection and then address each of them in turn.
- How complete are these genomes? We will rely on single copy genes for phylogenomic analysis so there is no reason to keep genomes that are missing too many genes.
- Do we need all of these genomes? It is likely that some of these genomes are highly similar to each other. What we are after is a representative sampling of Arcobacter genomic diversity.
Curate Genome Collection
The commands we ran above retrieved 124 genomes from the Arcobacter group. Here we perform a series of simple steps to eliminate unwanted or unecessary genomes from the collection.
We start with 125 genomes. This includes MAG02
We have two goals here. First, we need to get rid of low completion genomes since they will compromise our ability to use single copy core genes for phylogenomics. Second, we want to keep only genomes that have a 16S rRNA sequence. Why? Good question. Because we found an ASV in our 16S rRNA analysis that is 100% identical across it’s length to a 16S rRNA sequence retrieved from MAG02. In addition to the phylogenomic analysis we will also conduct a 16S rRNA analysis of MAG02 with publicly available genomes to see how the topologies compare.
Estimate Taxonomy
Microbial taxonomy is a fluid system, meaning that classifications change often. One thing we can do is look at the predicted taxonomy for each genome even though they each came prepackaged with a taxonomic designation. We already know MAG02’s predicted taxonomy is Poseidonibacter but what about the rest
To do this we will again run the command anvi-estimate-scg-taxonomy, which uses 22 ribosomal genes (Parks et al. 2018) from the Genome Taxonomy Database (GTDB) to estimate taxonomy. We added these classifications earlier when we contigs workflow. The workflow ran its own instance of anvi-run-scg-taxonomy for each genome. We can use a nifty for loop and then concatenate the output files and make a handy table. Pretty sure there is a better way :/
for genome in `cat list_genomes.txt`;
do
anvi-estimate-scg-taxonomy \
-c 03_CONTIGS/$genome-contigs.db \
-o 09_SCG_TAXONOMY/$genome-SCG.txt;
doneCompleteness
Let’s start by checking the completeness (and redundancy) of each genome based on the presence of single copy core genes (SCG) using the HMM profiles, which were added to the contig database for each genome during the workflow. We can either run the same command 125 times and concatenate the outputs, or we can create an external-genomes file—a two-column TAB-delimited flat text file that lists anvi’o contigs databases. The first item in the header line reads ‘name,’ and the second reads ‘contigs_db_path.’ Each line in the file describes a single entry, where the first column is the name of the genome (or MAG), and the second column is the anvi’o contigs database generated for this genome.
anvi-estimate-genome-completeness \
-e external-genomes.txt
-o completness.txtJust like that, a table of basic stats for every genome in the collection. First notice the completion estimate of MAG02 is around 93%, which is good, but its total length is among the smallest, meaning we have a pretty incomplete genome. Not so good but it is what it is.
Next, notice that 11 genomes have completion estimates lower than MAG02 (92.96%), in fact several have completion estimates of 0. These genome will be of no use to us since the phylogenomic analysis is based on SCG. These genomes are the first on our list to go. Another way to look at this is to generate a matrix of HMM hits across all genomes. For that we use the same external-genomes file but we need to also identify the HMM source we want anvi’o to return. Hum, what are the available HMM sources? Run the command with the --list-hmm-sources flag and anvi’o will tell you which HMM sources are common to all contig databases. You also need to give it an output file name or else the command will fail.
anvi-script-gen-hmm-hits-matrix-across-genomes
-e external-genomes.txt \
-o dummy_out.txt \
--list-hmm-sourcesHMM SOURCES COMMON TO ALL 125 GENOMES
===============================================
* Archaea_76 [type: singlecopy] [num genes: 976]
* Ribosomal_RNAs [type: Ribosomal_RNAs] [num genes: 244]
* Bacteria_71 [type: singlecopy] [num genes: 885]
* Transfer_RNAs [type: Transfer_RNAs] [num genes: 547]
* Protista_83 [type: singlecopy] [num genes: 1741]The HMM source we are interested in is Bacteria_71 (Lee 2019). Now, rerun the command and we get a table that lists the number of times each of the 71 HMM genes were found in each of the 125 genomes.
anvi-script-gen-hmm-hits-matrix-across-genomes
-e external-genomes.txt \
-o Bacteria_71-HMM_HITS.txt \
--hmm-source Bacteria_71
We added a column (total_hits) that records the total number of unique HMM genes per genome. This time notice that 11 genomes have fewer HMM hits than MAG02 (66). If you look at these two lists of genomes, they should be identical. Seems obvious but it isn’t always. These are two nice ways of looking at genome completeness. Now we can remove these genomes from our data set.
Now we have 114 genomes.
Screen for 16S rRNA
Remember, we found an ASV in our 16S rRNA analysis that was 100% identical to a 16S rRNA sequence retrieved from MAG02. So we also want to conduct a 16S rRNA analysis of MAG02 against publicly available genomes. It makes no sense (at least to me) to have a MAG02 16S tree that does not contain the same public genomes as the phylogenomic tree. Of the remaining genomes, which ones have a 16S rRNA sequence? We can go back to our old friend anvi-script-gen-hmm-hits-matrix-across-genomes but this time using the setting --hmm-source Ribosomal_RNAs. We also use a new external-genomes file with the 11 low HMM hit genomes removed.
anvi-script-gen-hmm-hits-matrix-across-genomes \
-e external-genomes-rrna-screen.txt \
-o Ribosomal_RNAs-HMM_HITS.txt \
--hmm-source Ribosomal_RNAsThere were 11 genomes without 16S rRNA genes. We can now remove these from the genome collection and generate a new external-genomes file containing only genomes with 16S rRNA sequences—external-genomes-rrna.txt. I hope you are starting to see that the external-genomes file is an important ally.
Now we have 103 genomes.
Using the command anvi-script-gen-hmm-hits-matrix-across-genomes allows us to retrieve the 16S rRNA sequences from each genome. Since several genomes have more than one copy, we use the --return-best-hit flag to return a single copy only. We add the flag --align-with muscle to generate a multiple sequence alignment for our inspection. Incidentally we could have used the flag --min-num-bins-gene-occurs and set it to 1 in this command, which would have removed any genomes without a 16S rRNA sequence. I figured that out after the fact.
anvi-get-sequences-for-hmm-hits
-e external-genomes-rrna.txt \
--hmm-sources Ribosomal_RNAs \
--gene-names Bacterial_16S_rRNA \
--no-wrap \
--return-best-hit \
--align-with muscle \
-o sequences-for-16s-rrna-hits.faThe sequence from Arcobacter_sp_BM504 was pretty short. Bye bye Arcobacter_sp_BM504.
Now we have 101 genomes.
Up to this point we have a collection consisting of genomes that have high completion and a full-length 16S rRNA sequence. What about redundant genomes? Surely there are some genomes that are highly similar, and we really only need a few representatives of each.
Dereplicate Genome Collection
Finally, we can dereplicate the genome collection using the command anvi-dereplicate-genomes to assess the number of genome clusters. This command has a lot of options for fine-tuning but since we are interested in a quick and dirty assessment, we’ll keep it simple. We can either give anvi’o an external-genomes file like we just did or a fasta-text-file similar to the one from the Snakemake workflow above. Remember, the external-genomes file provides names and paths to contig.dbs and the fasta-text-file provides names and paths to fasta files. Either way, we first need to remove the 11 genomes that we are cutting from the analysis. Let’s stick with the external-genomes file since we will use this downstream anyway.
Since accuracy is not paramount we use --program fastANI (Jain et al. 2018) because, well, it’s fast. We also need to choose a --similarity-threshold. We tested the number of clusters for 0.90, 0.95, 0.97, 0.98, and 0.99. Overkill? Maybe, but this will give us a good sense of replication in our genome collection. Here is the command with 0.97.
mkdir 06_DEREPLICATE
anvi-dereplicate-genomes -e external-genomes-rrna.txt
--program fastANI
--similarity-threshold 0.99
-o 06_DEREPLICATE/DR_99 -T $NSLOTSThe command produces numerous output files, but let’s focus on the CLUSTER_REPORT.txt file, which tells us the a) number of clusters, b) number of genomes in each cluster, c) representative genome for the cluster, and d) all genomes in the cluster.
How many clusters did we get for each --similarity-threshold?
- 0.900: 38 clusters
- 0.950: 44 clusters
- 0.970: 52 clusters
- 0.980: 60 clusters
- 0.990: 73 clusters
- 0.995: 76 clusters
We will use the genomes from the --similarity-threshold 0.99 to get rid of only genomes that are nearly identical.
Final collection contains 73 genomes.
Outgroup Workflow
We decided to use Sulfurimonas, a member of the Helicobacteraceae (Campylobacterales), as an outgroup for our tree. We basically ran the same pipeline as above, with a few minor changes. The code is included here but the discussion will be kept to a minimum. I am sure by this point you are tired of hearing me drone on and on.
1. Get TaxIDs
python gimme_taxa.py 202746 -o Sulfurimonas-TaxIDs-for-ngd.txt
python gimme_taxa.py 202746 -o Sulfurimonas-TaxIDs-for-ngd-just-IDs.txt \
--just-taxids2. Download genomes
ncbi-genome-download -t Sulfurimonas-TaxIDs-for-ngd-just-IDs.txt \
bacteria \
-o 00_Sulfurimonas_Genbank \
--metadata Sulfurimonas-NCBI-METADATA.txt \
-s genbank \
-l complete,chromosomeWe received 3 Sulfurimonas genomes. We used the -l complete,chromosome flag so we wouldn’t need to sift through a bunch of data. We only need a few genomes for the outgroup.
3. Format genomes
anvi-script-process-genbank-metadata -m Sulfurimonas-NCBI-METADATA.txt \
-o 01_Sulfurimonas-NCBI-GENOMES \
--output-fasta-txt Sulfurimonas-fasta.txt -\
-exclude-gene-calls-from-fasta-txt4. Run Snakemake workflow
You know the routine. Same steps performed for the Arcobacter.
5. Completeness
anvi-estimate-genome-completeness -e external-genomes-outgroup.txt \
-o completness-outgroup.txt6. Screen for 16S rRNA
anvi-script-gen-hmm-hits-matrix-across-genomes
-e external-genomes-outgroup.txt \
-o Ribosomal_RNAs-HMM_HITS-outgroup.txt \
--hmm-source Ribosomal_RNAs7. Retrieve 16S rRNA sequences
anvi-get-sequences-for-hmm-hits -e external-genomes-outgroup.txt \
--hmm-sources Ribosomal_RNAs \
--gene-names Bacterial_16S_rRNA \
--no-wrap --return-best-hit \
--align-with muscle \
-o sequences-for-16s-rrna-hits-outgroup.faWhich are full-length.
8. Dereplicate
mkdir 06_DEREPLICATE
anvi-dereplicate-genomes -e external-genomes-outgroup.txt \
--program fastANI \
--similarity-threshold 0.95 \
-o 06_DEREPLICATE/DR_95 -TGood to go, no duplicates. The outgroup consists of Sulfurimonas gotlandica (GD1), Sulfurimonas denitrificans (DSM 251), and Sulfurimonas autotrophica (DSM 16294).
Phylogenomic Analysis of MAG02
Finally, we are ready for phylogenomic analysis. One way to do this is to select SCG, make a concatenated alignment, and construct a multi locus tree. This is not the way we did it for the paper but it is worth seeing how it is done so you can appreciated the different approaches.
We first need to make a new external-genomes file that contains the Arcobacter representatives we want to use and the Sulfurimonas outgroup. Then we need to setup a phylogenomic Snakemake workflow.
Remember when ran the contigs workflow above? Most of those steps can actually be run in the phylogenomic workflow itself. The thing is that it does not really give us the opportunity to curate our collection before phylogenomic analysis. Because we ran the cotigs workflow first, there are many steps in the phylogenomic workflow that we simply do not need. So, we chop out the chunks of the phylogenomics-default-config.json that are unnecessary.
It seems like a good idea to select SCG that are in all of the genomes. First we generate a sample by SCG matrix.
anvi-script-gen-hmm-hits-matrix-across-genomes
-e arco-phylo-external-genomes.txt \
-o arco-phylo-Bacteria_71-HMM_HITS.txt \
--hmm-source Bacteria_71Of the 71 genes in the HMM profile, 64 were present in all 76 genomes. We used these genes for our analysis though we could easily select a subset like all Ribosomal genes.
Like before, we start by getting a default config file for the workflow. Modify the file how you like but make sure to add the genes file name (or a list of genes) to the config file.
anvi-run-workflow -w phylogenomics
--get-default-config phylogenomics-default-config.jsonAnd now here are the Snakemake commands.
anvi-run-workflow -w phylogenomics
-c phylogenomics-config.json
--additional-params
--jobs 5
--resources nodes=5
--keep-going --rerun-incomplete --unlock
anvi-run-workflow -w phylogenomics
-c phylogenomics-config.json
--additional-params
--jobs 5 --resources nodes=5
--keep-going --rerun-incompletePhylogenomic analysis of 73 Arcobacter and 3 Sulfurimonas genomes.
And away she goes. A straight-up phylogenomic approach using SCG (picked somewhat at random) as we just did may not be the best approach for scrutinizing closely related genomes. This is because we are not taking into account the degree of homogeneity within gene clusters. A better approach is to calculate homogeneity indices and use the results to guide the choice of genes clusters for the phylogenomic analysis. For this, we will use anvi’o pangenomic analysis.
Pangenome Analysis
For a pangenomic analysis we first need to generate a genome storage database, which is a special anvi’o database. Whatever you choose to name this database, it must have the extension -GENOMES.db. We generally followed this anvi’o workflow for microbial pangenomics when designing our workflow.
anvi-gen-genomes-storage -e arco-phylo-external-genomes.txt \
-o ARCOBACTER-GENOMES.dbAnd then we can run the pangenome analysis itself. We use the --min-occurrence flag set to 3 to ignore singleton and doubleton gene clusters.
anvi-pan-genome -g ARCOBACTER-GENOMES.db \
--min-occurrence 3 \
--project-name ARCOBACTER -T $NSLOTSAnvi’o will create gene cluster using the MCL (Markov Cluster) algorithm (Jain et al. 2018) and calculate homogeneity indices. Then we can visualize the results using the anvi’o interactive interface.
anvi-display-pan -g ARCOBACTER-GENOMES.db -p ARCOBACTER-PAN.dbOnce inside the interactive, we performed the following steps:
- Hit Draw and the pangenome will render in the browser window.
- Go to the Search pane and click on the Search gene clusters using filters dropdown.
- Set the following parameters:
- Min number of genomes gene cluster occurs = 76
- Min number of genes from each genome = 1
- Max number of genes from each genome = 1
- Max functional homogeneity index = 0.95
- Min geometric homogeneity index = 0.99
- Click Search.
- Scroll down and hit Highlight splits on tree. Zoom into that area on the outside of the tree. The red lines are the highlights.
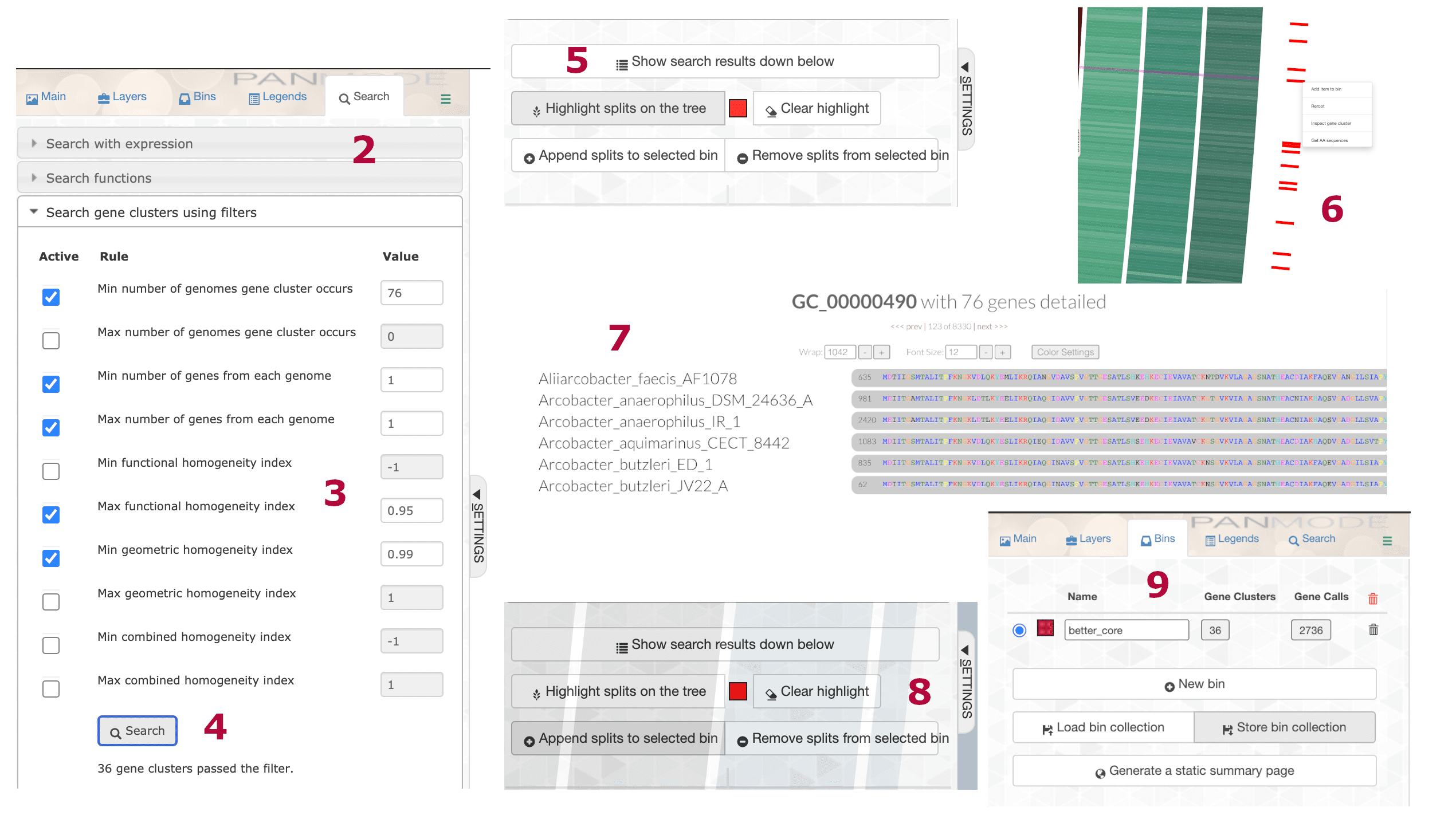
- Right click on a gene cluster and hit Inspect gene cluster.
- Check out the cluster, inspect others, make sure they look good.
- Head back to the button under Highlight and hit Append splits to the selected bin.
- Go to the Bins tab, rename the bin if you wish, and click Store bin collection.
We relaxed the functional homogeneity index to accommodate the outgroup. The pangenome database now has a new collection of SCG and a new phylogenomic tree. The new collection has 36 gene clusters and 2736 genes. 2736 divided by 76 (number of genomes) equals 36. Sweet.
Optional, on the fly tree generation.
If you wish, you can use the curated collection of gene clusters to generate a new tree right in the interface.
- Head over to the Layers tab and click Generate new phylogenetic tree.
- In the popup window make sure you like the settings and hit Generate.
Rather than using the tree generated on the fly by anvi’o, let’s get the sequences from the curated bin collection and do the analysis ourselves.
anvi-get-sequences-for-gene-clusters -p ARCOBACTER-PAN.db \
-g ARCOBACTER-GENOMES.db \
-C default -b better_core \
--concatenate-gene-clusters \
--align-with muscle \
-o ARCOBACTER-proteins-better-core.faUnder this scenario, anvi’o retrieves, aligns (in this case with MUSCLE (Edgar 2004)), and then concatenates the sequences.
It is important to note that everything we just in the interface can instead be done in the command line. If you look at the help menu for anvi-get-sequences-for-gene-clusters you will see that you can apply the filtering steps described above directly in the command line without the pangenomic interactive. Personally, I like to use the interactive because I can visually inspect each gene cluster to make sure nothing fishy is going on. The parameters you choose will depend on your question and the peculiarities of your data set, so play around.
Just for the fun of it, let’s have a look at what this entails without running interactive.
anvi-get-sequences-for-gene-clusters \
-p ARCOBACTER-PAN.db \
-g ARCOBACTER-GENOMES.db \
-o ARCOBACTER-proteins-better-core_no_interactive.fa \
--concatenate-gene-clusters \
--min-num-genomes-gene-cluster-occurs 76 \
--min-num-genes-from-each-genome 1 \
--max-num-genes-from-each-genome 1 \
--max-functional-homogeneity-index 0.95 \
--min-geometric-homogeneity-index 0.99And the last part of the output looks like this:
INFO
===============================================
Your filters resulted in 36 gene clusters that contain a total of 2736 genes.
for downstream analyses. Just so you know.
Sequence type ...............................................: Amino acid
Output file for phylogenomics ...............................: ARCOBACTER-proteins-better-core_no_interactive.faAs expected, 36 gene clusters encompassing a total of 2736 genes. Note, the order of genes in the concatenate file may differ but the content should be the same.
Anyway, regardless of the approach you choose, now we can use your curated SCG fasta file to construct a new phylogenomic tree. You can either do this is anvi’o, which will use IQ-TREE (Minh et al. 2020), or you can run a program outside anvi’o.
The anvi’o way…
anvi-gen-phylogenomic-tree -f ARCOBACTER-proteins-better-core.fa
-o ARCOBACTER-proteins-better-core.treGenerating & Visualizing Tree
Instead, we will use IQ-TREE (Minh et al. 2020) (v. 2.0.3) natively with ModelFinder Plus (Kalyaanamoorthy et al. 2017) to perform extended model selection followed by tree inference. ModelFinder computes the log-likelihoods of an initial parsimony tree for many different models then computes Akaike information criterion (AIC), corrected Akaike information criterion (AICc), and the Bayesian information criterion (BIC) to choose the substitution model that minimizes the BIC score.
iqtree -s ARCOBACTER-proteins-better-core.fa
--prefix arcobacterMFP
-m MFPModelFinder tested 51 models (it will test up to 546 protein models) and selected LG+F+R6 as the best-fit model based on BIC. We subsequently ran this model with 5000 ultrafast bootstrap approximations (Hoang et al. 2017).
iqtree -s ARCOBACTER-proteins-better-core.fa
--prefix arcobacterLG+F+R6-5000
-m LG+F+R6 -bb 5000 -T $NSLOTSGreat, we have a tree but really no other information to decorate it with. So far, we have generated a lot of metric data for each genome. Luckily, all of that is in the pangenome database. We use the command anvi-export-misc-data to get most what we need.
anvi-export-misc-data --pan-or-profile-db ARCOBACTER-PAN.db \
--target-data-table layers \
--output-file genome_stats.txtThis table contains things like total length, GC content, percent completion, percent redundancy, and so on. One piece we do not have by may want is the SCG taxonomy, speciffically the genus prediction. Clearly from what we have seen, these are not all Arcobacter, despite most genomes carrying that name.
We did this way back in the beginning, but let’s do it again for our final collection.
for genome in `cat final_genomes.txt`;
do
anvi-estimate-scg-taxonomy \
-c 03_CONTIGS/$genome-contigs.db \
-o 09_SCG_TAXONOMY/$genome-SCG.txt;
doneAnd add these data to our file with genome stats. Most of the lineage data is uninformative and can be eliminated. We also constructed a metadata file after sifting through all of the metadata we retrieved from NCBI about natural host and isolation source. We could combine these files but I like to keep the metadata file separate so I can add info as needed. Time to visualize.
Since we do not have a database, anvi’o will create a dummy database the first time we run the command anvi-interactive. But we still must give a name for the as yet nonexistent dadabase.
anvi-interactive --profile-db profile.db
--tree arcobacterLG+F+R6-5000.treefile
--manualStop the interactive. Now we have a database to populate. Let’s add the genome metric data.
anvi-import-misc-data genome_stats.txt
--pan-or-profile-db profile.db
--target-data-table itemsNow we can restart the interactive with our metadata file of NCBI collection info.
anvi-interactive --profile-db profile.db
--tree arcobacterLG+F+R6-5000.treefile
--additional-layers metadata.txt
--manualPhylogenetic Analysis of MAG02
Next, we performed the same process for 16S rRNA genes from all the genomes in the phylogenomic analysis.
anvi-get-sequences-for-hmm-hits
-e arco-phylo-external-genomes.txt \
--hmm-sources Ribosomal_RNAs \
--gene-names Bacterial_16S_rRNA \
--no-wrap \
--return-best-hit \
--align-with muscle \
-o sequences-for-16s-rrna-hits.faThe fasta output of this command needs a little TLC before continuing because anvi’o adds a bunch of info to the deflines about the gene. Good info to have but if we use this file in an external program like RAxML, all of this info becomes the name and I am sure you would not like to look at a tree with leaves like this:
|>Bacterial_16S_rRNA_Ribosomal_RNAs_2c53c82ce374e7c1bd22dd51720f5f90b9f43fdfb6b3b3d6cb0623b9 bin_id:Aliiarcobacter_faecis_AF1078|source:Ribosomal_RNAs|e_value:0|
We used BBEdit and some grep search and replace to extract the sample names.
Next, we again ran IQ-TREE (Minh et al. 2020) (v. 2.0.3) with ModelFinder Plus (Kalyaanamoorthy et al. 2017) to perform extended model selection followed by tree inference.
iqtree -s sequences-for-16s-rrna-hits-rename.fa
--prefix arcobacter-16s-MFP
-m MFPModelFinder tested 29 models (it will test up to 286 DNA models) and selected TVM+F+I+G4 as the best-fit model based on BIC. We subsequently ran this model with 5000 ultrafast bootstrap approximations (Hoang et al. 2017).
iqtree -s sequences-for-16s-rrna-hits-rename.fa
--prefix arcobacter-16s-TVM+F+I+G4
-m TVM+F+I+G4 -bb 5000If you are unfamiliar with IQ-TREE, check out the tutorial. It’s a really nice program.
Genome Metadata
Here is the metadata for record of all genomes used in phylogenomic analysis of MAG02. Table contains information for each of the 72 Arcobacter-like genomes (plus 3 outgroup genomes). Description of table headers are as follows.
genome_id: Name of genome in phylogenomic tree.
isolation_category: Broad category based on host/isolation source information retrieved from the BioSample record.
organism: Organism name retrieved from the BioSample record.
strain_or_isolate: Genome stain or isolate designation.
sample_information: Host/isolation source information retrieved from the BioSample record.
bioproject: NCBI BioProject ID.
biosample: NCBI BioSample ID.
assembly_accession: NCBI Assembly ID.
taxid: NCBI Taxonomy ID.
species_taxid: NCBI Species Taxonomy ID.
doi_publication: DOI link for related publication.
assembly_level: Assembly level.
seq_rel_date: Genome release data.
ftp_path: FTP link to download genome.
submitter: Submitting Institution.
A plain text version of this table (without HTML tags) can be downloaded here.
Conclusion
Dandy. Now we have a phylogenomic tree of MAG02 with 72 other Arcobacter genomes and 3 from Sulfurimonas as the outgroup. We also have a phylogenetic tree of near-full length 16S rRNA genes from the same genomes.
Source Code
The source code for this page can be accessed on GitHub by clicking this link.
Data Availability
Files generated from the pangenomic (01_MAG02_PAN/), phylogenomic (02_MAG02_PHYLOGENOMICS), and 16S rRNA phylogenetic (03_MAG02_16S_rRNA_PHYLOGENETICS) analyses of MAG02 can be downloaded from figshare at doi:10.25573/data.12809561. You can use the anvi’o commands described above to visualize the data.
In the analysis, this MAG is named WATER_MAG_00002. For brevity we refer to it henceforth as MAG02↩︎